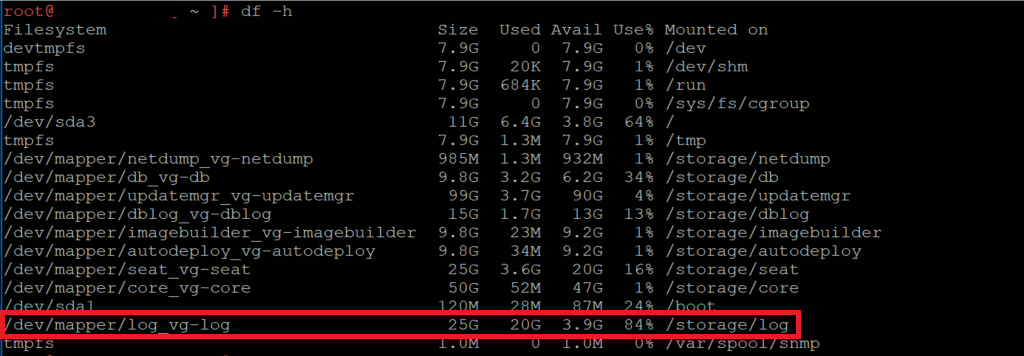
A while back I was welcomed to the office by a vCenter Server Appliance critical health alert, specifically, ‘The /storage/log filesystem is out of disk space or inodes’. This error is usually due to a failed automated log clean-up process, so in this article I detail how to implement a temporary ‘get out of jail’ fix, followed by a more permanent fix with the identification of the offending files and how to tidy them up.
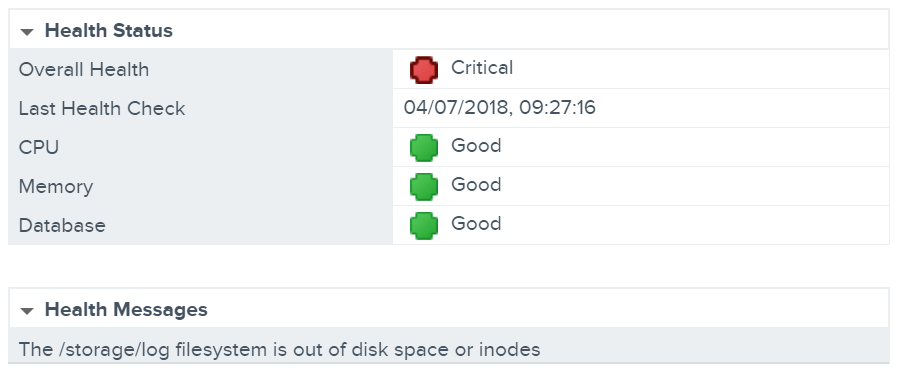
Firstly, let’s take a look at the file system itself in order to confirm our UI findings. SSH onto the VCSA appliance and enter BASH, then list all available file systems via the df -h command. From the below screenshot the UI warning has been confirmed, specifically, the file system in question has been completely consumed.

The ‘Get Out of Jail’ Temporary Fix
In the unfortunate event that this issue is preventing you from accessing vCenter, we can implement a quick fix by extending the affected disk. Note, this is a quick fix only and should be implemented to restore vCenter access only. This should not be relied on as a permanent resolution.
As we have already identified the problematic disk, jump over to the vSphere client and extend the disk in question (you call by how much, but in my environment, I’ve added an additional 5 GB). This leaves us the final task of initiating the extension and enabling the VCSA to see the additional space. Depending on your VCSA version, there are two options:
VCSA v6.0
vpxd_servicecfg storage lvm autogrow
VCSA v6.5 and 6.7
/usr/lib/applmgmt/support/scripts/autogrow.sh
Lastly, list all file systems to confirm the extension has been realised.
Permanent Fix
So, we’re out of jail, but we still have an offending consumer. In my instance, checking within the file system identified a number of large log files. These hadn’t been cleared automatically by the VCSA so a manual intervention was required. Specifically, the removal of localhost_access_log, vmware-identity-sts, and vmware-identity-sts-perf logs was required. These can be removed via the below command.
rm log-file-name.*

Following the removal, another df -h show’s we’re back in business.

Lastly, and in this instance, restart the Security Token Service to initiate the creation of new log files.
service vmware-stsd restart

Further Reading
For this specific issue, please see VMware KB article 2143565, however, if in doubt, do call upon the VMware Support. The team will be able to assist you in identifying the offending files/directories which can be safely removed.
thanks!
olso works on vcenter appliance 6.7
This saved me. Thank you for publishing this. I didn’t realize that the one mount of drives could bring a company down!
It’s always the little things!
Great post – got us out of a serious jam. We could not power on VMs because of the log files “stuck” in the SSO directory
Glad to hear it helped Bryan. Like you, I experienced this the ‘bad way’.
Great article and thank you. Following your article I was able to free up 4% of space. I was wondering what else I can safely remove? Thank you
———————————————————————-
localhost:/storage/log # df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 11G 6.1G 4.1G 60% /
udev 4.0G 164K 4.0G 1% /dev
tmpfs 4.0G 44K 4.0G 1% /dev/shm
/dev/sda1 128M 41M 81M 34% /boot
/dev/mapper/core_vg-core 25G 7.2G 17G 31% /storage/core
/dev/mapper/log_vg-log 9.9G 8.9G 475M 96% /storage/log
/dev/mapper/db_vg-db 9.9G 304M 9.1G 4% /storage/db
/dev/mapper/dblog_vg-dblog 5.0G 267M 4.5G 6% /storage/dblog
/dev/mapper/seat_vg-seat 9.9G 507M 8.9G 6% /storage/seat
/dev/mapper/netdump_vg-netdump 1001M 18M 932M 2% /storage/netdump
/dev/mapper/autodeploy_vg-autodeploy 9.9G 151M 9.2G 2% /storage/autodeploy
/dev/mapper/invsvc_vg-invsvc 5.0G 168M 4.6G 4% /storage/invsvc
——————————————————————————
localhost:/storage/log # du -h
4.0K ./remote
16K ./lost+found
12K ./vmware/vws/watchdog-vws
16K ./vmware/vws
48K ./vmware/sso/utils
388M ./vmware/sso
517M ./vmware/vmafdd
4.0K ./vmware/vctop
29M ./vmware/invsvc
756K ./vmware/vmdir
84K ./vmware/vdcs/vdcserver
3.5G ./vmware/vdcs
370M ./vmware/vsphere-client/logs/access
403M ./vmware/vsphere-client/logs
412M ./vmware/vsphere-client
76K ./vmware/vsm/web
46M ./vmware/vsm
245M ./vmware/vmcad
104K ./vmware/applmgmt/applmgmt-audit
4.5M ./vmware/applmgmt
1.8G ./vmware/cloudvm
4.0K ./vmware/vapi-endpoint
180M ./vmware/perfcharts
8.0K ./vmware/vmafd
37M ./vmware/iiad
268M ./vmware/vmware-sps
24K ./vmware/syslog/watchdog-syslog
9.4M ./vmware/syslog
16K ./vmware/vpxd/watchdog-vpxd
21M ./vmware/vpxd/drmdump/domain-c76
21M ./vmware/vpxd/drmdump
88K ./vmware/vpxd/inventoryservice-registration
4.0K ./vmware/vpxd/uptime/error
8.0K ./vmware/vpxd/uptime
555M ./vmware/vpxd
28K ./vmware/rbd
32K ./vmware/vpostgres/watchdog-vmware-vpostgres
200K ./vmware/vpostgres
20K ./vmware/rhttpproxy/watchdog-rhttpproxy
5.6M ./vmware/rhttpproxy
4.0K ./vmware/mbcs
40K ./vmware/psc-client/utils
1.6M ./vmware/psc-client
11M ./vmware/vsan-health
4.0K ./vmware/netdumper
76K ./vmware/eam/web
11M ./vmware/eam
92K ./vmware/rsyslogd
5.2M ./vmware/cm/firstboot
4.0K ./vmware/cm/work/Tomcat/localhost/ROOT
8.0K ./vmware/cm/work/Tomcat/localhost
12K ./vmware/cm/work/Tomcat
16K ./vmware/cm/work
16M ./vmware/cm
2.9M ./vmware/cis-license/history
50M ./vmware/cis-license
101M ./vmware/workflow
36M ./vmware/vapi/endpoint
36M ./vmware/vapi
4.0K ./vmware/sca/work/Tomcat/localhost/ROOT
8.0K ./vmware/sca/work/Tomcat/localhost
12K ./vmware/sca/work/Tomcat
16K ./vmware/sca/work
537M ./vmware/sca
88M ./vmware/vmdird
8.8G ./vmware
8.8G .
Great news Michael! This post has certainly been interesting to follow in terms of replies. Remember though, this is only a get of jail card. Once you’ve got your VCSA back up and running, I’d suggest logging a support call with GSS (if you haven’t already) to finalise the issue. Also, the following KB might help further – https://kb.vmware.com/s/article/2143565.